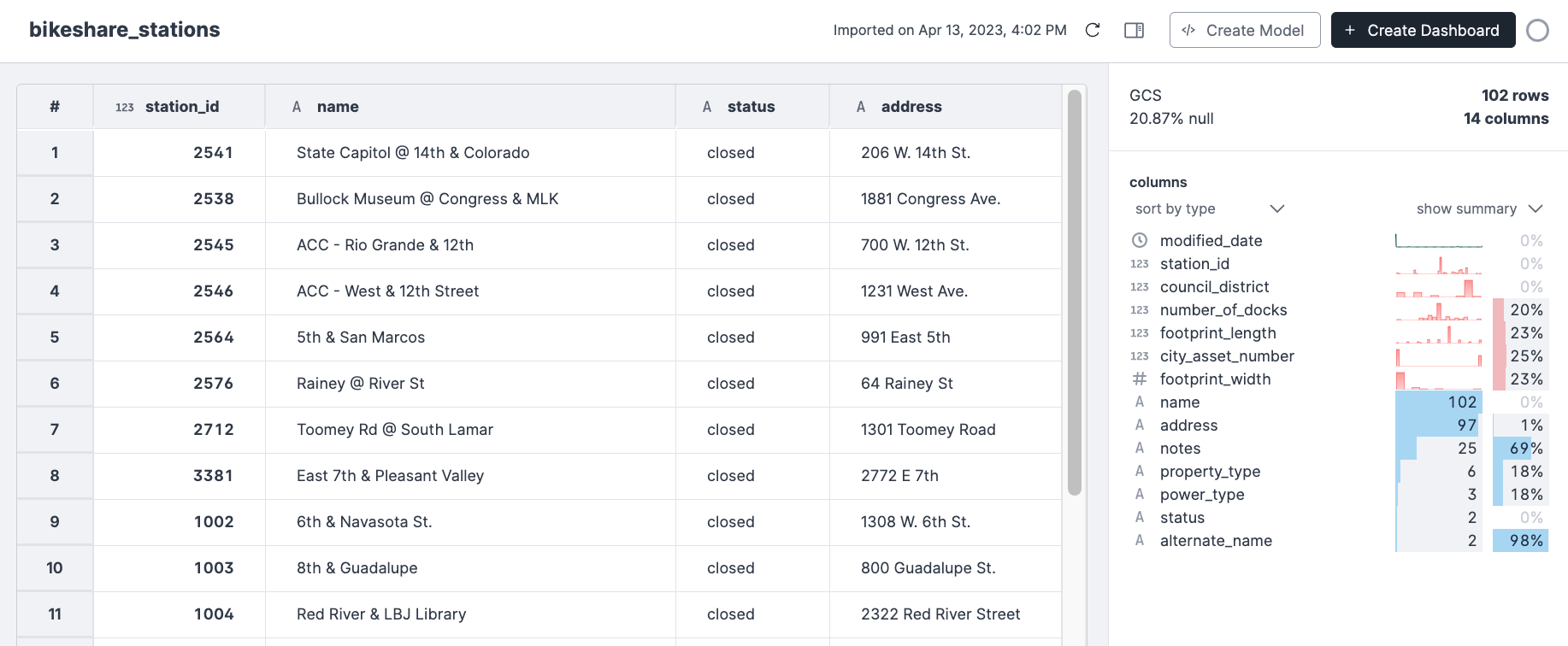
Get your bigquery data into rill

You need a CSV or Parquet file to load into Rill (https://docs.rilldata.com/using-rill/import-data). Here are steps and caveats you can follow to get a dataset in Bigquery into that format and processed with Rill. Much of the guidance here is from the Rill team themselves. The approach we take is to set up an export job in bigquery and make it a scheduled query:
Scheduling queries - https://cloud.google.com/bigquery/docs/scheduling-queries
Export statement - https://cloud.google.com/bigquery/docs/reference/standard-sql/other-statements#export_data_statement
We'll assume you have a GCS bucket ready. This blog uses the rilldemo bucket:
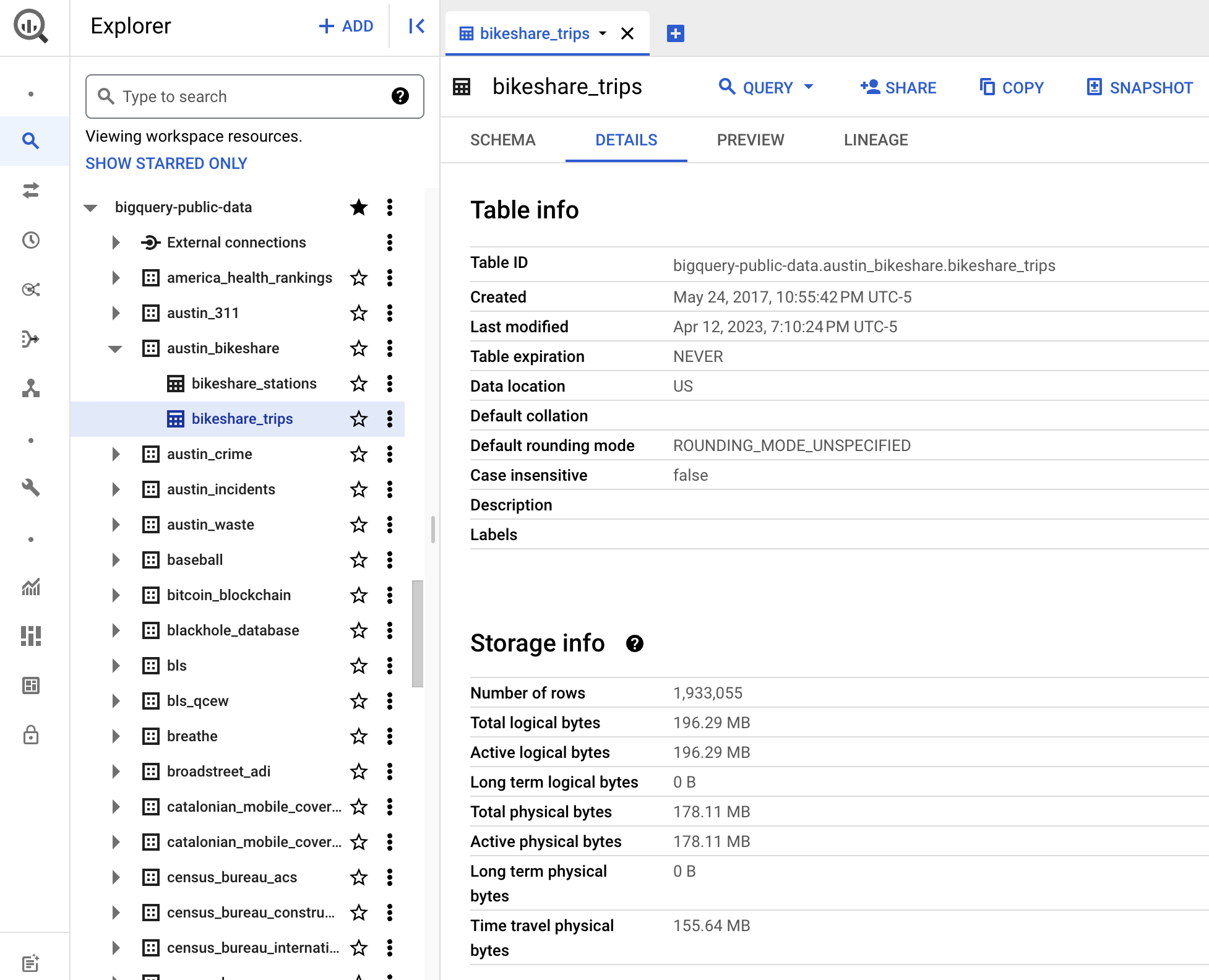
We'll demo syncing the austin_bikeshare.bikeshare_stations and austin_bikeshare.bikeshare_trips datasets from the Austin Bikeshare data in the Google Bigquery public datasets:
We'll write the following two queries (note that a single scheduled query can run multiple export statements - but you can also separate them out if you'd like different exports scheduled at different times. In this case its easy enough to pull all exports together in one query):

For copy and pasting:
EXPORT DATA
OPTIONS (
uri = 'gs://rilldemo/bigquery-public-data/austin_bikeshare/bikeshare_stations_*.parquet',
format = 'PARQUET',
overwrite = true,
compression = 'gzip'
)
AS (
SELECT DISTINCT * FROM bigquery-public-data.austin_bikeshare.bikeshare_stations
);
EXPORT DATA
OPTIONS (
uri = 'gs://rilldemo/bigquery-public-data/austin_bikeshare/bikeshare_trips_*.parquet',
format = 'PARQUET',
overwrite = true,
compression = 'gzip'
)
AS (
SELECT * FROM bigquery-public-data.austin_bikeshare.bikeshare_trips LIMIT 10000000
);
The important caveats here are that the uri must use the .parquet extension (and does not need the .gz at the end even if it is gzipped). The second caveat is that we should use either DISTINCT * (which forces bq to compute the data in a single node) or LIMIT 1000000 (some really large number to help inform bigquery about how large the output might be), to try to force bigquery to output a single parquet file. If the DISTINCT * or LIMIT 1000000 are missing bigquery may process multiple parquet files in the output destination. Normally this is accptable since rill can pickup wildcard files, however it is a problem if you don't delete all the items in the bucket before hand. If for instance the query first generates 10 parquet files but on subsequent runs only 8 files, then their will be 8 files that are fresh and 2 that are stale. However rills wildcard file input will pick up all ten in the bucket. An approach to fix this issue if you do have data that spans more than 1 parquet file could be orchestrating the deletion of all files in the bucket and then running the EXPORT DATA commands yourself in a cronjob to make sure all files are from the same EXPORT run, and stale files aren't left over.
Now we schedule it:
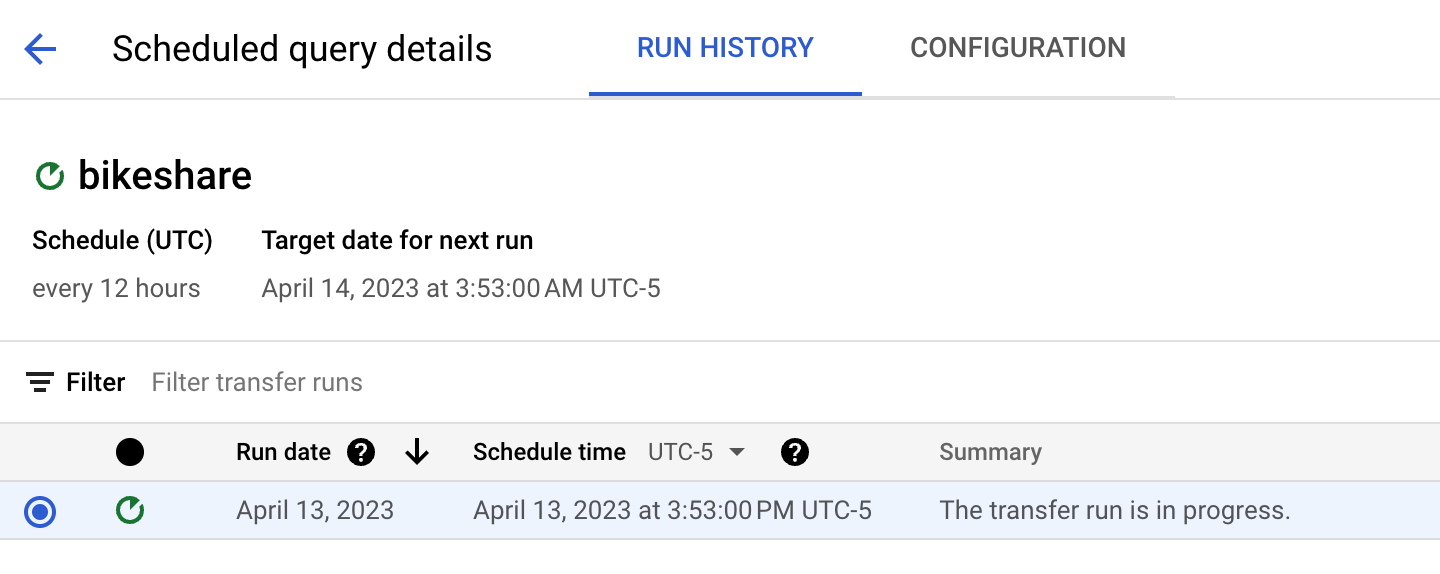
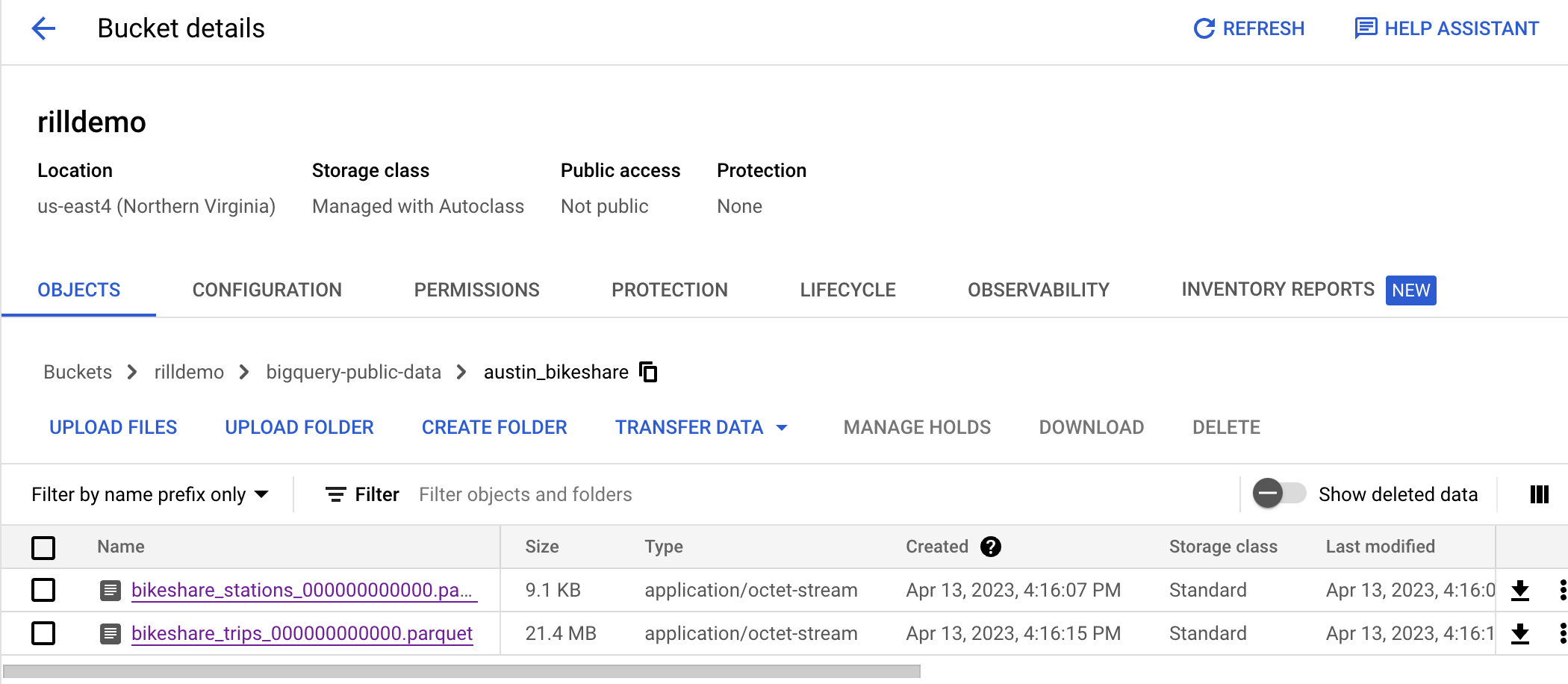
The run will create our parquet files as two standalone files (vs segmented ones):
Now get gcloud installed and authenticated:
brew install --cask google-cloud-sdk
gcloud auth application-default login
brew install rilldata/tap/rill
Now inside the Rill UI:
➜ ~ rill start
2023-04-13T15:54:01.209-0500 INFO Hydrating project '/Users/me'
2023-04-13T15:54:01.795-0500 INFO Reconciled: /dashboards/model_dashboard.yaml
2023-04-13T15:54:01.795-0500 INFO Hydration completed!
2023-04-13T15:54:01.822-0500 INFO Serving Rill on: http://localhost:9009
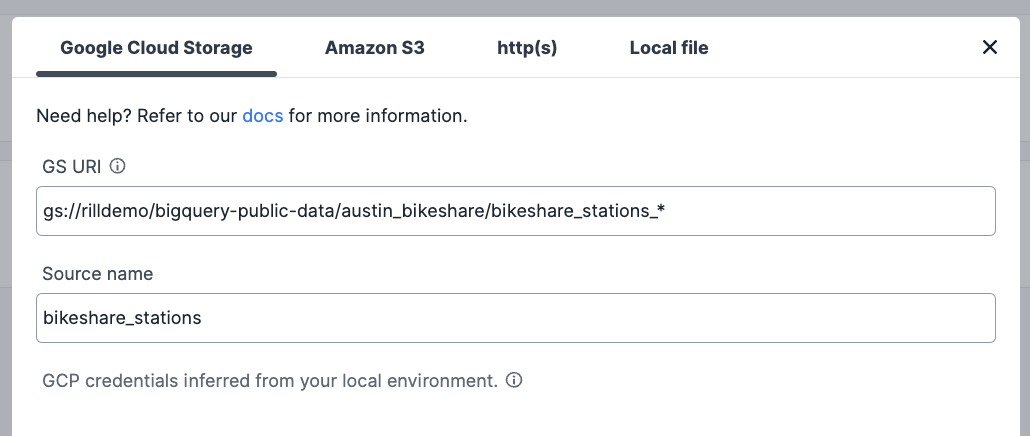
Now load the source (another annoying caveat is you can't postfix the wildcard here which is why the word parquet isn't in the image below - rill quirk):
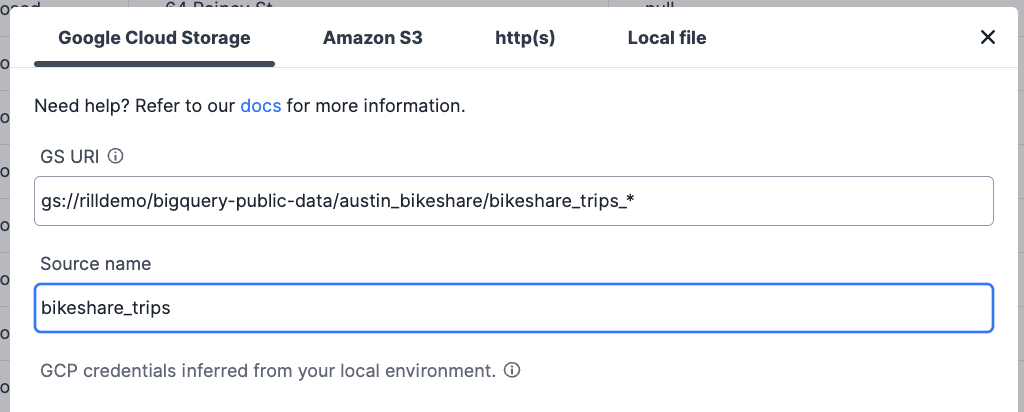
And now finally you have periodically updated data in Rill from Bigquery. Phew... I truly wish this was an easier process and am a bit suprised at how many little caveats and gotchas you run into along the way of just trying to see your bigquery data in rill.